OSWorld2.0 Benchmarks AI Agents on Complex Real-World Computer Tasks.
▶ The 2-minute explainer
Summary
OSWorld2.0 introduces a new benchmark designed to evaluate AI agents' ability to perform long-horizon, real-world computer usage tasks. The associated paper details the methodology and findings of this benchmarking effort.
Why it matters
Professionals developing or deploying AI agents need robust benchmarks like OSWorld2.0 to accurately assess agent capabilities for complex, multi-step tasks in real-world environments.
How to implement this in your domain
- 1Review the OSWorld2.0 paper to understand the benchmark's scope and methodology.
- 2Integrate OSWorld2.0 into your agent development pipeline for rigorous testing.
- 3Analyze agent performance on long-horizon tasks to identify areas for improvement.
- 4Contribute to the benchmark by sharing new tasks or agent implementations.
- 5Use the benchmark results to guide future research and development of more capable agents.
Who benefits
Key takeaways
- OSWorld2.0 provides a critical benchmark for evaluating AI agents on real-world computer tasks.
- The benchmark focuses on long-horizon tasks, reflecting complex human-computer interaction.
- It helps identify strengths and weaknesses of current AI agent architectures.
- This research is vital for advancing the development of more autonomous and capable agents.
Original post by @_akhaliq
"OSWorld2.0 Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks paper:"
View on XPrimary sources
Originally posted by @_akhaliq on X · view source
Want to go deeper?
Turn these trends into skills with Learnijoy's hands-on AI & tech courses.
Explore coursesMore in AI Research
GeneBench-Pro: New AI Benchmark for Biological Data Navigation
A new research-level benchmark, GeneBench-Pro, has been introduced to evaluate AI agents' ability to handle complex biological data, select appropriate analysis methods, and make critical judgments in computational research.

ASPIRE: Robots Learn and Share Skills Continuously
ASPIRE introduces a self-evolving skills library for robots, enabling them to continuously learn and refine tasks by observing sensory data and distilling know-how. This approach significantly improves sim-to-real and cross-embodiment transfer by sharing strategies rather than raw data or weights.
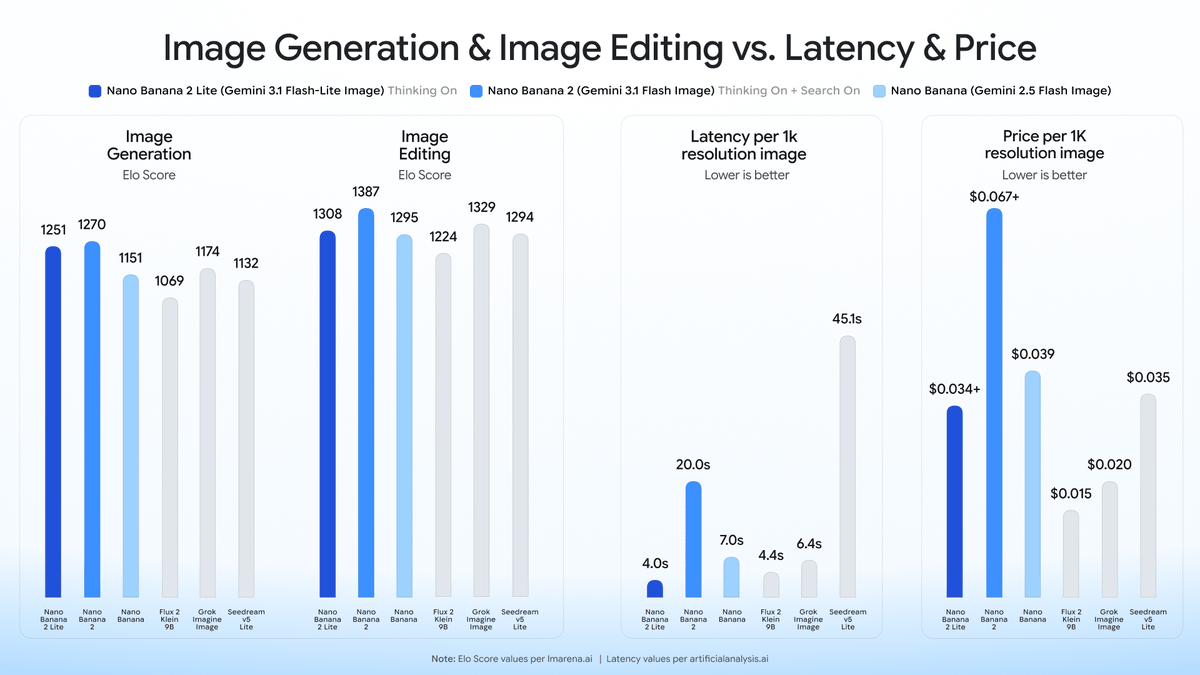
Google Launches New Image and Video AI Models
Google has released Nano Banana 2 Lite for rapid, cost-effective image generation and Gemini Omni Flash, a high-performing video generation and editing model. While Gemini Omni Flash leads in text-to-video, OpenAI's gpt-image-2 maintains its top position for image generation.